Image Output
Annotation Example
Source (Python)
Image Output

Annotation Example

Source (Python)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 | # Loop through each icon image in src icon images list for idx, image_file in enumerate(os.scandir(src_image_dir)): offset = [0,0] counter = 0 img_name = image_file.name # Read overlay image and resize it to smaller image overlay = cv2.imread(image_file.path, cv2.IMREAD_UNCHANGED) overlay = cv2.resize( overlay, overlay_size ) object_name = img_name.replace('.png', '') print('Generating samples for: {}'.format(object_name)) # Format the path variables from the object_name annotations_path = input_annotations_path dst_image_dir = os.path.join(input_dst_image_dir) dst_image_dir += '\\' annotations_path += '\\' print('Writing samples to {}'.format(dst_image_dir)) print('Writing annotations to {}'.format(annotations_path)) if not os.path.isdir(input_dst_image_dir): os.mkdir(input_dst_image_dir) print('Creating output directory for {}'.format(input_dst_image_dir)) if not os.path.isdir(input_annotations_path): os.mkdir(input_annotations_path) print('Creating output directory for {}'.format(input_annotations_path)) if not os.path.isdir(dst_image_dir) : os.mkdir(dst_image_dir) if not os.path.isdir(annotations_path) : os.mkdir(annotations_path) while(counter < total_count): # Choose a random background image from the bg list bg_file_name = GetRandomFileNameInDir( bg_image_dir ) bg_image_path = os.path.join(bg_image_dir, bg_file_name) bg_choice = random.randint(0, len(bg_images) - 1) bg = bg_images[bg_choice] result = bg # Sprinkle other heroes num_heroes_to_sprinkle = random.randint(0, 9) for idx in range(num_heroes_to_sprinkle): hero_icon_idx = random.randint(0, len(images) - 1) hero_icon = images[hero_icon_idx] offset[0] = random.randint(0, bg.shape[0] - hero_icon.shape[0]) offset[1] = random.randint(0, bg.shape[1] - hero_icon.shape[1]) result = GenerateOverlayImage( result, hero_icon, offset ) # Generate a random offset depending on size of the smaller image and larger image offset[0] = random.randint(0, bg.shape[0] - overlay.shape[0]) offset[1] = random.randint(0, bg.shape[1] - overlay.shape[1]) # Generate the overlaid image result = GenerateOverlayImage( result, overlay, offset ) out_img_name = '{}_{}.jpg'.format(object_name, counter) out_path = os.path.join(dst_image_dir, out_img_name) # Annotations topLeft = [offset[1], offset[0]] botRight = [offset[1] + overlay.shape[1], offset[0] + overlay.shape[0]] folder_tag = 'images' WriteXMLv2(folder_tag, result, out_img_name, out_path, [object_name], topLeft, botRight, annotations_path) print('Offset:{} --- DestImage:{}'.format(offset, out_path)) # Add noise if enabled if random.random() < enable_noise: noise_gen.noisy('s&p', result) # Write the image to file cv2.imwrite( out_path, result, [int(cv2.IMWRITE_JPEG_QUALITY), 100]) counter += 1 |
Source (Python)
JSON Output
Source (Python)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 | # Initializes a classifier network for the label def init_classifier( label ): label_str = label.lower() options = { "model": 'cfg/tiny-yolo-voc-1c-' + label_str + '.cfg', "load": 3100, "gpu": 0.8, "labels": 'data/individual_detectors/' + label + '/labels.txt', "threshold": 0.2, } classifier_network = TFNet(options) return classifier_network if __name__=="__main__"": for label in labels: frame_counter = 1 # init the network classifier = init_classifier(label) # Iterate through each frame described in the input json for frame_obj in match_frames[1:]: # Seek to the frame number frame_num = int(frame_obj["Frame"]) capture.set(cv2.CAP_PROP_POS_FRAMES, frame_num) # Capture each frame isValid, frame = capture.read() if (isValid == False): break # Check if hero is alive and skip this loop if not is_alive = frame_obj["Champions"][label]["is_alive"] if is_alive == False: bbox = box([0,0], [0,0], False) champions_obj = frame_obj["Champions"] champions_obj[label]["Position"] = bbox.get_center() champions_obj[label]["Bbox"] = { "TopLeft": bbox.topleft, "BotRight": bbox.botright } frame_counter += 1 progress_percent = (frame_counter / totalFrames) * 100 sys.stdout.write("\rLabel:{} Progress: {:.0f}%".format(label, progress_percent)) sys.stdout.flush() continue # Classify image prediction_result = classify_frame_with_network( frame, classifier ) # Get bounding box details for the obj bbox = get_bbox_for_obj_from_prediction(label, prediction_result) center = bbox.get_center() champions_obj = frame_obj["Champions"] champions_obj[label]["Position"] = center champions_obj[label]["Bbox"] = { "TopLeft": bbox.topleft, "BotRight": bbox.botright } frame_counter += 1 |
JSON Output
The CNN system only fills in the Position field in the JSON file. The other fields are part of the input json file that’s generated from the other UI elements.


Death Location Comparison (Scatterplot)
Death Locations (Minimap)
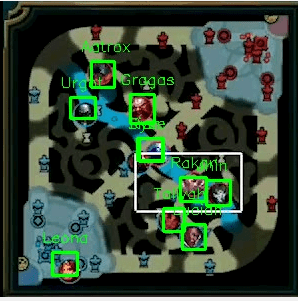
Bounding Box Visualizer
Death Location Comparison (Scatterplot)
The comparison between the death locations obtained from the League of Legends API and the computer vision system. Blue shows API data. Orange shows Computer Vision(CV) data.

Death Locations (Minimap)
Computer Vision Data (Left) and League of Legends API (Right)

Bounding Box Visualizer